c++ Multithreading programming 学习(5)

这一节我来学习一下一些更高级的用法。首先回想一下以前我们是如何进行跨线程取值的,我们需要通过共享的变量,用condition varible来提醒其他线程取值,或者通过mutex以及共享变量来组合传递变量的更改状态。或者也可以通过future promise来完成。
| API | C++标准 | 说明 |
|---|---|---|
| async | C++11 | 异步运行一个函数,并返回保有其结果的std::future |
| future | C++11 | 等待被异步设置的值 |
| packaged_task | C++11 | 打包一个函数,存储其返回值以进行异步获取 |
| promise | C++11 | 存储一个值以进行异步获取 |
| shared_future | C++11 | 等待被异步设置的值(可能为其他 future 所引用) |
future & promise
- promise non-copyable, moveable
- future also non-copyable but can become a shared_future, which is copyable
- promise 只能设置value,不能读取
- future 只能读value,不能设置
他们的工作流程如图:
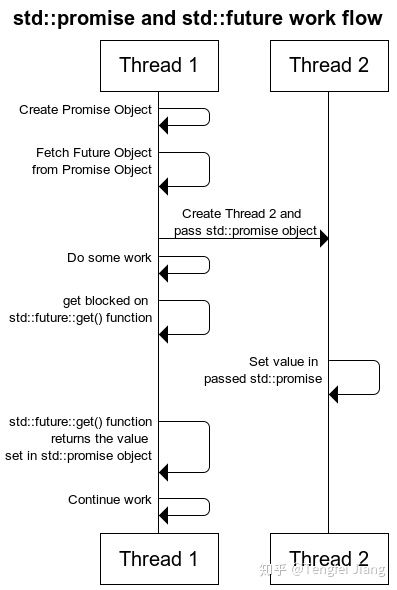
线程1创建promise对象,并从该promise对象中获得对应future对象。线程1将promise对象传递给线程2,继续自己的工作直到堵塞在future::get()。线程2接受传入的promise对象,通过set_value()(或其他set函数)设定特定值,然后继续自己其他的工作。一旦将结果设置到promise上,其相关联的future对象就会处于就绪状态。需要注意的是,future对象只要被一个线程通过get()取值,再之后就没有可获取的值了,如果从多个线程调用get()会导致竞争,undefined behavior。如果需要从多个线程获取future结果需要使用shared_future。
example
#include <future>
#include <iostream>
#include <thread>
#include <utility>
void multiplier(std::promise<int>&& intPromise, int a, int b){
intPromise.set_value(a*b);
}
void divider() (std::promise<int>&& intPromise, int a, int b) {
intPromise.set_value(a/b);
}
int main(){
int a= 20;
int b= 10;
std::cout << std::endl;
// define the promises
std::promise<int> prodPromise;
std::promise<int> divPromise;
// get the futures
std::future<int> prodFutureResult= prodPromise.get_future();
std::future<int> divFutureResult= divPromise.get_future();
// calculate the result in a separat thread
std::thread prodThread(multiplier,std::move(prodPromise),a,b);
std::thread divThread(divider,std::move(divPromise),a,b);
// get the result
std::cout << "20*10= " << prodFutureResult.get() << std::endl;
std::cout << "20/10= " << divFutureResult.get() << std::endl;
prodThread.join();
divThread.join();
std::cout << std::endl;
}
packaged_task
在一些业务中,我们可能会有很多的任务需要调度。这时我们常常会设计出任务队列和线程池的结构。此时,就可以使用packaged_task来包装任务。packaged_task绑定到一个函数或者可调用对象上。当它被调用时,它就会调用其绑定的函数或者可调用对象。并且,可以通过与之相关联的future来获取任务的结果。调度程序只需要处理packaged_task,而非各个函数。
packaged_task对象是一个可调用对象,它可以被封装成一个std::fucntion,或者作为线程函数传递给std::thread,或者直接调用。packaged_task中可以传入函数对象,函数指针,lambda函数等。注意,这些函数并不是在package_task构造时被执行,需要手动invoke,才能执行。可以在当前线程执行,也可以被move到其他线程。
example
double concurrent_worker(int min, int max) {
double sum = 0;
for (int i = min; i <= max; i++) {
sum += sqrt(i);
}
return sum;
}
double concurrent_task(int min, int max) {
vector<future<double>> results; // ①
unsigned concurrent_count = thread::hardware_concurrency();
min = 0;
for (int i = 0; i < concurrent_count; i++) { // ②
packaged_task<double(int, int)> task(concurrent_worker); // ③
results.push_back(task.get_future()); // ④
int range = max / concurrent_count * (i + 1);
thread t(std::move(task), min, range); // ⑤
t.detach();
min = range + 1;
}
cout << "threads create finish" << endl;
double sum = 0;
for (auto& r : results) {
sum += r.get(); // ⑥
}
return sum;
}
int main() {
auto start_time = chrono::steady_clock::now();
double r = concurrent_task(0, MAX);
auto end_time = chrono::steady_clock::now();
auto ms = chrono::duration_cast<chrono::milliseconds>(end_time - start_time).count();
cout << "Concurrent task finish, " << ms << " ms consumed, Result: " << r << endl;
return 0;
}
在这段代码中:
- 首先创建一个集合来存储future对象。我们将用它来获取任务的结果。
- 同样的,根据CPU的情况来创建线程的数量。
- 将任务包装成packaged_task。请注意,由于concurrent_worker被包装成了任务,我们无法直获取它的return值。而是要通过future对象来获取。
- 获取任务关联的future对象,并将其存入集合中。
- 通过一个新的线程来执行任务,并传入需要的参数。
- 通过future集合,逐个获取每个任务的计算结果,将其累加。这里r.get()获取到的就是每个任务中concurrent_worker的返回值。
async
async 是更上层的封装
template< class Function, class... Args >
std::future<std::invoke_result_t<std::decay_t<Function>,
std::decay_t<Args>...>>
async( std::launch policy, Function&& f, Args&&... args );
template< class Function, class... Args>
std::future<std::invoke_result_t<std::decay_t<Function>,
std::decay_t<Args>...>>
async( Function&& f, Args&&... args );
std::launch policy 有两种:async 或 deferred。两者的区别在于,async是在新线程中异步执行,通过返回的future的get函数来取值。而deferred 是在当前线程中同步执行,但请注意,并不是立即执行,而是延后到get函数被调用的时候才执行,这种取值的行为又被称为lazy evaluation。没有std::launch的重载版本表现如同以 policy 为 std::launch::async | std::launch::deferred 调用 。换言之, f 可能执行于另一线程,或者它可能在查询产生的 std::future 的值时同步运行。
example
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
#include <future>
#include <string>
#include <mutex>
std::mutex m;
struct X {
void foo(int i, const std::string& str) {
std::lock_guard<std::mutex> lk(m);
std::cout << str << ' ' << i << '\n';
}
void bar(const std::string& str) {
std::lock_guard<std::mutex> lk(m);
std::cout << str << '\n';
}
int operator()(int i) {
std::lock_guard<std::mutex> lk(m);
std::cout << i << '\n';
return i + 10;
}
};
template <typename RandomIt>
int parallel_sum(RandomIt beg, RandomIt end)
{
auto len = end - beg;
if (len < 1000)
return std::accumulate(beg, end, 0);
RandomIt mid = beg + len/2;
auto handle = std::async(std::launch::async,
parallel_sum<RandomIt>, mid, end);
int sum = parallel_sum(beg, mid);
return sum + handle.get();
}
int main()
{
std::vector<int> v(10000, 1);
std::cout << "The sum is " << parallel_sum(v.begin(), v.end()) << '\n';
X x;
// Calls (&x)->foo(42, "Hello") with default policy:
// may print "Hello 42" concurrently or defer execution
auto a1 = std::async(&X::foo, &x, 42, "Hello");
// Calls x.bar("world!") with deferred policy
// prints "world!" when a2.get() or a2.wait() is called
auto a2 = std::async(std::launch::deferred, &X::bar, x, "world!");
// Calls X()(43); with async policy
// prints "43" concurrently
auto a3 = std::async(std::launch::async, X(), 43);
a2.wait(); // prints "world!"
std::cout << a3.get() << '\n'; // prints "53"
} // if a1 is not done at this point, destructor of a1 prints "Hello 42" here