cpu affinity 亲和性

CPU Affinity
cpu affinity 就是让某个进程/线程绑定在某个cpu(core)上,使其尽量长时间的运行而不被迁移到其他core上的倾向性。 Linux kernel提供了两个api来修改或查看某个进程/线程的亲和性:
int sched_setaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);
int sched_getaffinity(pid_t pid, size_t cpusetsize, cpu_set_t *mask);
如果pid是0,那么默认是当前thread。
cpu_set_t 是一个掩码数组,共1024位,每一位对应一个core,以下宏是对这个掩码进行操作的:
void CPU_ZERO (cpu_set_t *set)
这个宏对 CPU 集 set 进行初始化,将其设置为空集。
void CPU_SET (int cpu, cpu_set_t *set)
这个宏将 cpu 加入 CPU 集 set 中。
void CPU_CLR (int cpu, cpu_set_t *set)
这个宏将 cpu 从 CPU 集 set 中删除。
int CPU_ISSET (int cpu, const cpu_set_t *set)
如果 cpu 是 CPU 集 set 的一员,这个宏就返回一个非零值(true),否则就返回零(false)。
我看到很多人说对于thread我们用pthread_setaffinity_np, 对于process我们才用sched_setafinity.于是我仔细的看了一下。首先,sched_setaffinity的man page上写的是
A thread's CPU affinity mask determines the set of CPUs on which it is eligible to run
当然它也写了
(If you are using the POSIX threads API, then use pthread_setaffinity_np(3) instead of sched_setaffinity().)
当我们使用
int pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, const cpu_set_t *cpuset);
int pthread_getaffinity_np(pthread_t thread, size_t cpusetsize, cpu_set_t *cpuset);
我们传入的是pthread_t. 而当我们使用sched_setaffinity时,我们传进去的可以是pid from getpid(),也可以是tid from gettid().(对于单线程的进程,pid等于tid,对于多线程的进程,每个线程有不同的tid,但会有相同的pid。)pid_t 和pthread_t是不同的,pthread_t是同一个进程中各个线程之间的标识号,对于这个进程内是唯一的,而不同进程中,每个线程返回的pthread_t可能是一样的。而gettid是用来系统内各个线程间的标识符,由于linux采用轻量级进程实现的,它其实返回的应该是pid号。 还有需要注意的就是当你给一个线程设置了亲和性然后pthread_create 其他线程,其他线程会继承当前这个线程的亲和性。不过在我的工作范围内,sched_setaffinity 已经足够,因为线程的创建是固定的,我们也需要在创建后设置亲和性,所以不必担心亲和性的继承问题。
BTW: gettid() is not implemented in glibc, 所以我们需要用syscall去获取tid
pid_t getThreadId()
{
return syscall(__NR_gettid);
}
Hyperthreading & NUMA
现代cpu会有多个core,每个core可能会支持两个线程。可以通过lscpu 或者lstopo 查看。比如这张网上的图片。
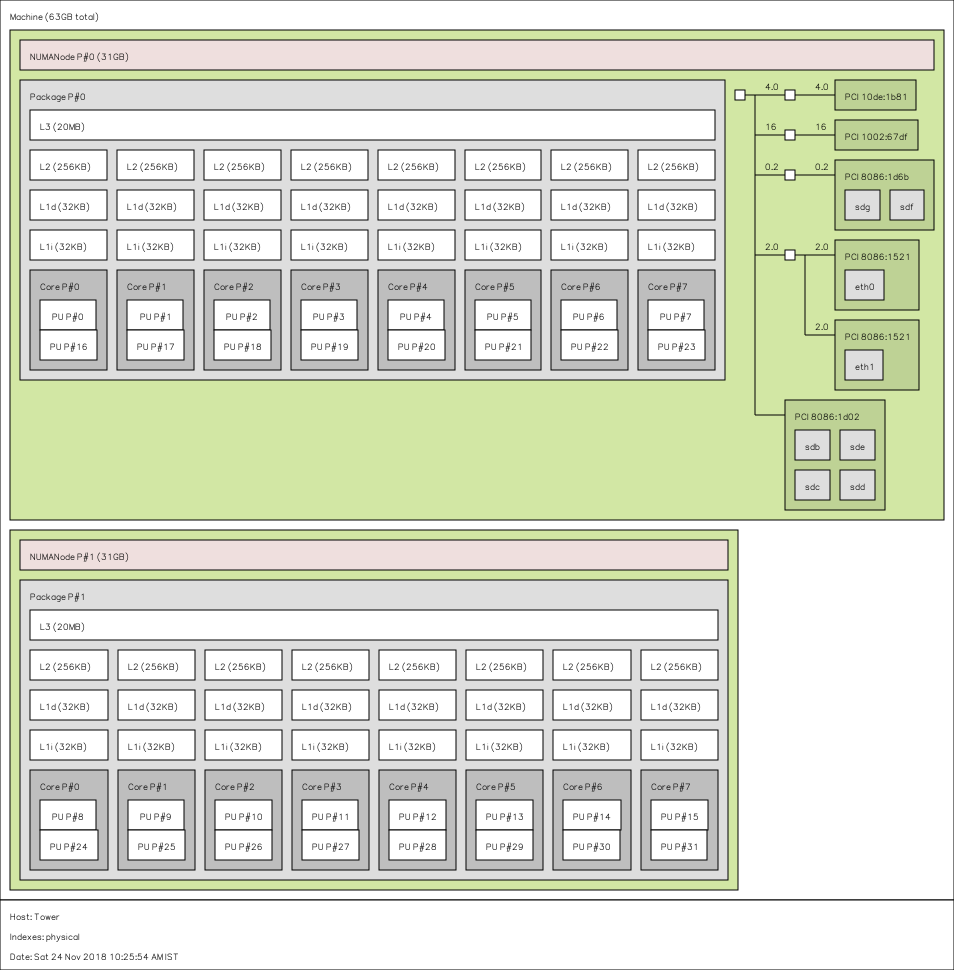
在一些强大的工作站上会有不止一个scoket,比如我工作的机器有两个sockets,每个socket有8个core。如果hyperthreading(HT) enabled,那就将有32个hardware thread. 他们处在不同的numa(非统一内存访问架构)下(即某些cpu之间松散连接着,甚至不共享memory and bus)。那么hardware thread共享什么呢,又怎么关系到我们的程序呢?看上图,每个core内的两个threads会共享L1 和 L2 cache,同一个socket下的所有核会共享L3。 对于multi-socket机器,通常来讲每个socket有自己L3cache。对于NUMA,每个processor会访问自己的DRAM,不同processor之间通过一些通信机制来互相访问(QPI). 可以看到HT仅仅是在物理核心上使用了两个物理任务描述符,却没有增加实际的物理计算能力。 他的好处在于如果两个程序被调度到了同一个core,他们可以共享cache和TLB来降低任务切换开销。但是如果两个程序需要抢夺物理执行资源,那么反而会增加延时。对于低延迟交易来讲,我认为disable这个更好,因为它会损害性能增高延迟。但是对于互联网来讲,这个可以提高吞吐量,所以在互联网业务中,可以依据具体业务决定是否enable。对于不同numa来说,他们访问彼此的cache要明显慢于访问自己的cache, 可以通过命令numactl -H查看,这给我们的启发是尽量让相关的任务处在同一个numa node下。
查看cpu信息
查看处理器核数:cat /proc/cpuinfo | grep "cpu cores" | uniq 即每个物理处理器的core的个数,例如Intel(R) Xeon(R) CPU E5-2690 @2.90GHz在每个socket上有8 cores
查看逻辑处理器核数 :cat /proc/cpuinfo, 如果siblings和cpu cores一致,则不支持超线程
查看物理处理器封装id:cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l 例如Intel(R) Xeon(R) CPU E5-2690 @2.90GHz 有两个"物理处理器封装"
查看逻辑处理器ID: cat /proc/cpuinfo | grep "processor" | wc -l 例如Intel(R) Xeon(R) CPU E5-2690 @2.90GHz 没有开超线程,他有两个物理处理器封装。每个封装有8个core,则一共含有16个core/逻辑处理器(如果开了HT就是32).其id从0 -15.
线程独占
即使将线程绑定到了某个core,系统依然可能将其他任务调度到这个核,为了进一步减少其他任务对这个线程的影响,我们可以将这个core从内核调度系统中剥离。
在 /boot/grub2.cfg中输入isolcpu=11,12或者你想剥离的cpu id,这样系统启动后将不会使用这两个core, 当然,通过taskset我们还是可以指定一些程序在这些核运行。
或者换个思路,我们将init.d限制在core 0, 这样由它产生的所有进程都会运行在这个core上,而对于一些特定的进程,我们可以指定他们到其他core上。我们可以default_affinity=0或者init=/usr/bin/numactl -m 0 -c 0 /sbin/init。后者比前者好因为它同时绑定了core 0 并设置了numa policy 表明更偏爱node 0 的memory allocation。taskset -pc 1来看我们确实设置成功。需要注意如果一个进程有RT优先级的话会锁住,所以对于这样的进程要在其他核运行。
Reference
https://zhuanlan.zhihu.com/p/33324549
https://zhuanlan.zhihu.com/p/33621500
https://eli.thegreenplace.net/2016/c11-threads-affinity-and-hyperthreading/